1 JUC简述 介绍 JUC实际上就是我们对于jdk中java.util.concurrent 工具包的简称。这个包下的类都是和 **Java多线程开发 **相关的类。
查看JDK的官方文档如下所示:
2 线程的创建方式 2.1 继承Thread类 2.1.1 代码演示 通过继承Thread类来创建并启动多线程的步骤如下:
1、定义一个类,让其继承Thread类
2、重写Thread类中的的run方法(该run方法的方法体就代表了线程需要完成的任务。因此把run方法称之为线程执行体)
3、创建Thread子类的实例,即创建了线程对象
4、调用线程对象的start()方法来启动该线程
线程类:
1 2 3 4 5 6 7 8 9 10 11 public class MyThread extends Thread { @Override public void run () { for (int x = 0 ; x < 100 ; x++) { System.out.println(x); } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 public class ThreadDemo1 { public static void main (String[] args) { MyThread t1 = new MyThread () ; t1.start(); } }
如果我们需要再开启一个线程,那么怎么办呢?
再次创建一个线程对象
调用start方法启动线程
1 2 3 4 5 6 7 8 9 10 11 12 public class ThreadDemo2 { public static void main (String[] args) { MyThread t1 = new MyThread () ; MyThread t2 = new MyThread () ; t1.start(); t2.start(); } }
经过测试,查看控制台打印结果;发现多次运行程序的结果并不相同,原因是因为CPU在多个线程间进行切换,随机执行导致的结果。
结论:多线程的执行具有随机性。
2.1.2 执行图解 多线程程序执行图解
当我们执行main方法时候,此时jvm会开启一个线程去执行,一个线程可以看做是程序的一条执行路径;当我们在main方法中又开启了两个线程,并且将其启动起来,那么此时在程序中会存在3条执行路径。它们之间彼此都是独立的,进行同时执行。
单线程程序执行图解
对比我们之前所线程的单线程程序,那么程序在执行的时候,只存在一条执行路径
2.1.3 start和run区别 start方法和run方法的区别如下:
1、调用start方法,jvm会开启一个线程(新的路径)去执行run方法中代码;
调用run方法就是把run方法当做普通方法去执行,jvm不会去开启一个新线程来执行。
2、start方法只能调用一次,run方法可以调用多次。
代码演示1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ThreadDemo3 { public static void main (String[] args) { MyThread t1 = new MyThread () ; t1.run(); for (int x = 0 ; x < 100 ; x++) { System.out.println("main ------>>> " + x); } } }
调用t1对象的run方法时,程序的执行结果就是每一次都是等待run方法执行完毕了,才去执行main方法中的for循环;
当调用t1对象的start方法时,程序的执行结果就具有随机性,因此就说明直接调用run方法jvm就没有去开启一个线程去执行。
代码演示2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ThreadDemo4 { public static void main (String[] args) { MyThread t1 = new MyThread () ; t1.start(); t1.start(); } }
以上程序会出现如下错误
1 2 3 Exception in thread "main" java.lang.IllegalThreadStateException at java.base/java.lang.Thread.start(Thread.java:794 ) at com.atguigu.javase.thread.create.demo01.ThreadDemo4.main(ThreadDemo4.java:13 )
代码演示3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ThreadDemo5 { public static void main (String[] args) { MyThread t1 = new MyThread () ; t1.run(); t1.run(); } }
以上程序不会报错,可以进行正常执行。
2.2 Thread类核心API 2.2.1 线程名称 1 2 3 public final String getName () public final void setName (String name) public Thread (String name)
2.2.2 线程对象 获取当前正在执行该方法的线程对象:
1 public static native Thread currentThread () ;
2.2.3 线程休眠 1 2 public static void sleep (long time) TimeUnit.时间单位.sleep(时间值);
2.2.4 线程加入 把某一个线程加入到当前线程的执行流程中。
1 public final void join () throws InterruptedException
当某一个程序执行流程中调用了其他线程的join()方法,调用线程暂停执行,直到被join()方法加入的join线程执行完成为止。
比如现在存在两个线程,一个t1线程 , 一个是t2线程,当我们t1线程执行到某一个时刻的时候,我们在t1线程的执行流中添加了t2线程,那么此时t1线程暂停执行,直到t2线程执行完毕以后t1线程才可以继续执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ThreadDemo01 { public static void main (String[] args) { for (int x = 0 ; x < 100 ; x++) { if (x == 10 ) { MyThread myThread = new MyThread (); myThread.setName("atguigu-01" ); myThread.start(); try { myThread.join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(Thread.currentThread().getName() + "--------->>" + x); } } }
控制台输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 main--------->>0 main--------->>1 main--------->>2 main--------->>3 main--------->>4 main--------->>5 main--------->>6 main--------->>7 main--------->>8 main--------->>9 atguigu-01 ----->>> 0 atguigu-01 ----->>> 1 atguigu-01 ----->>> 2 atguigu-01 ----->>> 3 atguigu-01 ----->>> 4 .... atguigu-01 ----->>> 98 atguigu-01 ----->>> 99 main--------->>10 main--------->>11 main--------->>12 ....
通过控制台的输出结果,我们可以看到当主线程输出完9以后,”atguigu-01”线程加入到了主线程的执行流程中,此时主线程处于等待状态。当被加入的线程执行完毕以后,主线程的阻塞状态才会被消除。
面试题:有三个线程 T1 , T2 , T3 ,如何保证顺序执行?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static void main (String[] args) throws InterruptedException { Thread t1 = new Thread (()->{ System.out.println(111 ); }); Thread t2 = new Thread (()->{ System.out.println(222 ); }); Thread t3 = new Thread (()->{ System.out.println(333 ); }); t1.start(); t1.join(); t2.start(); t2.join(); t3.start(); t3.join(); }
2.2.5 线程中断 (1)interrupt方法 当调用线程的sleep方法时,可以让该线程处于等待状态,调用该线程的interrupt()方法就可以打断该阻塞状态 ,中断阻塞状态以后,继续执行(前提是别throw),而不是让线程结束,并且此方法会抛出一个InterruptedException异常。
1 public void interrupt () ;
案例:演示中断sleep的等待状态
线程类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MyThread extends Thread { @Override public void run () { for (int x = 0 ; x < 100 ; x++) { System.out.println(Thread.currentThread().getName() + "----" + x ); if (x == 10 ) { try { TimeUnit.SECONDS.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ThreadDemo1 { public static void main (String[] args) { MyThread t1 = new MyThread (); t1.setName("atguigu-01" ); t1.start(); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } t1.interrupt(); } }
控制台输出结果
1 2 3 4 5 6 7 8 9 ... atguigu-01 ----10 java.lang.InterruptedException: sleep interrupted at java.base/java.lang.Thread.sleep(Native Method) at java.base/java.lang.Thread.sleep(Thread.java:339 ) at java.base/java.util.concurrent.TimeUnit.sleep(TimeUnit.java:446 ) at com.atguigu.javase.thread.api.demo14.MyThread.run(MyThread.java:14 ) atguigu-01 ----11 ...
通过控制台的输出结果,我们可以看到interrupted方法并没有去结束当前线程,而是将线程的阻塞状态中断了,中断阻塞状态以后,线程atguigu-01继续进行执行。
(2)stop方法 调用线程的stop方法可以让线程终止执行 ,没有异常。
1 public final void stop ()
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class MyThread extends Thread { @Override public void run () { for (int x = 0 ; x < 100 ; x++) { System.out.println(Thread.currentThread().getName() + "----" + x ); if (x == 10 ) { try { TimeUnit.SECONDS.sleep(10000 ); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ThreadDemo1 { public static void main (String[] args) { MyThread t1 = new MyThread (); t1.setName("atguigu-01" ); t1.start(); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } t1.stop(); } }
控制台输出结果
1 2 3 ... atguigu-01 ----9 atguigu-01 ----10
控制台没有任何异常输出,程序结束,”atguigu-01”线程没有继续进行执行。
2.2.6 守护线程 (1)概述 有一种线程是在后台运行的,它的任务就是为其他的线程提供服务,这种线程被称之为”后台线程”,又被称之为”守护线程”。
后台线程的特征:如果所有的前台线程都结束,后台线程会自动结束,前后台线程都结束了,JVM就退出了。
常见的前台线程:主线程、之前创建的自定义线程…
(2)创建守护线程 创建普通线程,调用其setDaemon(true)方法,即创建了守护线程。
1 public final void setDaemon (boolean on)
Thread的子类
1 2 3 4 5 6 7 8 9 public class MyThread extends Thread { @Override public void run () { for (int x = 0 ; x < 100 ; x++) { System.out.println(Thread.currentThread().getName() + "----" + x ); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class ThreadDemo01 { public static void main (String[] args) { MyThread t1 = new MyThread (); t1.setName("关羽" ); MyThread t2 = new MyThread (); t2.setName("张飞" ); t1.setDaemon(true ); t2.setDaemon(true ); t1.start(); t2.start(); Thread.currentThread().setName("---------------刘备" ); for (int x = 0 ; x < 5 ; x++) { System.out.println(Thread.currentThread().getName() + "-----" + x); } } }
控制台输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 张飞----0 张飞----1 张飞----2 张飞----3 张飞----4 关羽----0 关羽----1 关羽----2 关羽----3 关羽----4 关羽----5 关羽----6 关羽----7 ---------------刘备-----0 关羽----8 ---------------刘备-----1 张飞----5 ---------------刘备-----2 关羽----9 ---------------刘备-----3 张飞----6 ---------------刘备-----4 关羽----10 关羽----11 关羽----12 关羽----13 关羽----14 关羽----15 关羽----16 关羽----17 关羽----18 关羽----19 关羽----20 Process finished with exit code 0
最理想的状态就是当主线程(所有前台线程)执行完毕以后,所有守护线程(t1线程和t2线程)就应该立即结束。
但是控制台的输出结果是主线程打印结束后,守护线程还在继续打印一些内容。
为什么呢?因为前台线程全部结束后,JVM会通知后台线程全部结束,但从它接收到指令到做出响应,需要一定时间,而在这一段时间内其他线程还可以继续执行。
2.3 Runnable接口 2.3.1 创建Runnable接口实现类 实现多线程的第二种方式就是借助于Runnable接口进行实现,具体的步骤如下:
1、定义Runnable接口的实现类,并重写该接口的run方法
2、创建Runnable实现类的实例
3、创建Thread对象,然后将第二步创建实例作为参数传递过来
4、调用start方法启动线程
1 2 3 4 5 6 7 8 9 10 11 12 public class MyRunnable implements Runnable { @Override public void run () { for (int x = 0 ; x < 100 ; x++) { System.out.println(x); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ThreadDemo01 { public static void main (String[] args) { MyRunnable myRunnable = new MyRunnable () ; Thread t1 = new Thread (myRunnable) ; Thread t2 = new Thread (myRunnable) ; t1.start(); t2.start(); } }
2.3.2 匿名内部类实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ThreadDemo01 { public static void main (String[] args) { Thread t1 = new Thread (new Runnable () { @Override public void run () { } }) ; Thread t2 = new Thread (new Runnable () { @Override public void run () { } }) ; t1.start(); t2.start(); } }
2.3.3 Lambda 表达式 1 2 3 4 Thread thread = new Thread (() -> { System.out.println(Thread.currentThread().getName()); }); thread.start();
什么是函数式接口?
2.4 Callable接口 2.4.1 概述 从java5开始,Java提供了Callable接口,该接口提供了一个call方法,并且有返回值。
但是我们并不能直接将Callable对象作为Thread的构造方法的参数进行传递,为啥?类型不匹配。咋办?借助FutureTask。
FutureTask是Runnabla的子类。
2.4.2 代码实现 需求:开启一个线程计算1-100之和
Callable接口的子类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class MyCallable implements Callable <Integer> { @Override public Integer call () throws Exception { int result = 0 ; for (int x = 1 ; x <= 100 ; x++) { result += x ; } return result; } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class CallableDemo1 { public static void main (String[] args) throws ExecutionException, InterruptedException { MyCallable myCallable = new MyCallable () ; FutureTask<Integer> futureTask = new FutureTask <Integer>(myCallable) ; Thread thread = new Thread (futureTask) ; thread.start(); Integer integer = futureTask.get(); System.out.println(integer); } }
2.5 创建线程3种方式总结 1、直接继承Thread类,线程和任务合并在一起,代码简单,但扩展性差,因为Java是单继承。
2、实现Runnable接口或者Callable接口。线程和任务进行了分离,扩展性强,我们的任务类还可以继续继承某一个类。
3、Runnable接口中的run方法没有返回值也没有异常,Callable中的call方法存在返回值也声明了异常。
3 线程安全问题 线程安全问题概述:当多个线程对共享数据操作 的时候此时就是出现数据错乱的问题,我们把这种问题就称之为线程安全问题!
3.1 线程安全问题演示-抢红包 案例演示:
需求:使用多线程模拟抢红包案例,4个人抢3个红包
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class RedPackageThread implements Runnable { private static int redPackageCount = 3 ; @Override public void run () { if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "-->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"-->抢到一个红包,剩余个数:" + --redPackageCount); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class RedPackageThreadDemo01 { public static void main (String[] args) { RedPackageThread redPackageThread = new RedPackageThread () ; Thread t1 = new Thread (redPackageThread , "张三" ) ; Thread t2 = new Thread (redPackageThread , "李四" ) ; Thread t3 = new Thread (redPackageThread , "王五" ) ; Thread t4 = new Thread (redPackageThread , "赵六" ) ; t1.start(); t2.start(); t3.start(); t4.start(); } }
1 2 3 4 张三---->抢到了一个红包,剩余红包个数:2 赵六---->抢到了一个红包,剩余红包个数:1 李四---->抢到了一个红包,剩余红包个数:0 王五---->抢到了一个红包,剩余红包个数:-1
这里的-1怎么出现的?
3.2 解决问题思路 解决线程安全的思路: 就是将多个线程对共享数据的并发访问更改为串行访问 。
串行 访问(同步 访问)就是指:一个共享数据一次只能被一个线程访问,该线程访问完毕以后其他的线程才可以访问。
要实现共享数据的串行 访问,我们就需要使用锁 机制来完成。
相关概念:
1、获取锁/申请锁:一个线程在访问共享数据之前,我们必须要申请锁,申请锁的这个过程我们将其称之为获取锁。
2、持有锁的线程: 一个线程获得了某一个锁,我们就将该线程称之为锁的持有线程。
3、临界区:获取锁 到 释放锁,这个区间称之为“临界区”,共享数据只能在临界区内进行访问,临界区一次只能被一个线程执行。
锁的持有线程可以对该锁所保护的共享数据进行访问,访问结束以后该线程就需要释放锁。
3.3 隐式锁(synchronized) 1 synchronized 实现的加锁和释放锁是自动的,不需要显示执行,称之为“隐式锁”
3.3.1 synchronized (1)synchronized概述 synchronized锁是Java中用于控制 多线程访问共享资源 的工具。
它可以用来修饰 代码块 或者 方法 ,确保在同一时刻只有一个线程可以执行被修饰的代码。
当线程尝试获取锁时,如果锁被其他线程持有,那么当前线程会被阻塞,直到锁被释放。
同步代码块的格式 :
1 2 3 4 synchronized (对象) { } 该对象可以是任意的对象,这个对象可以简单的理解就是一把锁,但是需要保证多个线程在访问的时候使用的是同一个对象。
同步方法的格式
1 2 public synchronized void sellTicket () {...}public static synchronized void sellTicket () {...}
(2)同步代码块改造 需求:使用同步代码块改造上述的代码,保证多线程操作共享数据的的安全性!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class RedPackageThread implements Runnable { private static int redPackageCount = 3 ; private static final Object lock = new Object () ; @Override public void run () { synchronized (lock){ if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); } } } }
注意:多个线程所使用的锁对象必须是同一个!
1 2 3 4 张三---->抢到了一个红包,剩余红包个数:2 王五---->抢到了一个红包,剩余红包个数:1 李四---->抢到了一个红包,剩余红包个数:0 赵六---->未抢到红包
(3)同步方法改造 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override public void run () { getRedPackage(); } private synchronized void getRedPackage () { if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); } }
(4)静态同步方法改造 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static synchronized void getRedPackage () { if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); } }
(5)锁对象研究 思考问题:同步代码块、同步方法、静态同步方法的锁对象分别是谁?
1、普通同步方法,是实例锁,锁是当前实例对象。
2、静态同步方法,是类锁,锁是当前类的Class对象。
3、同步代码块,锁是synchonized括号里配置的对象。
3.3.2 死锁现象 线程死锁是指由于两个或者多个线程互相持有对方所需要的资源,导致这些线程处于等待状态,无法前往执行。
锁接口
1 2 3 4 5 public interface MyLock { public static final Object R1 = new Object () ; public static final Object R2 = new Object () ; }
Thread的子类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class DeadThread extends Thread { private boolean flag; public DeadThread (boolean flag) { this .flag = flag; } @Override public void run () { if (flag) { synchronized (MyLock.R1) { System.out.println(Thread.currentThread().getName() + "---获取到了R1锁,申请R2锁...." ); synchronized (MyLock.R2) { System.out.println(Thread.currentThread().getName() + "---获取到了R1锁,获取到了R2锁...." ); } } } else { synchronized (MyLock.R2) { System.out.println(Thread.currentThread().getName() + "---获取到了R2锁,申请R1锁...." ); synchronized (MyLock.R1) { System.out.println(Thread.currentThread().getName() + "---获取到了R2锁,获取到了R1锁...." ); } } } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 public class DeadThreadDemo1 { public static void main (String[] args) { DeadThread deadThread1 = new DeadThread (true ) ; deadThread1.setName("线程1" ); DeadThread deadThread2 = new DeadThread (false ) ; deadThread2.setName("线程2" ); deadThread1.start(); deadThread2.start(); } }
控制台输出结果
1 2 Thread-0 ---获取到了R1锁,申请R2锁.... Thread-1 ---获取到了R2锁,申请R1锁....
此时程序并没有结束,这种现象就是死锁现象…线程Thread-0持有R1的锁等待获取R2锁,线程Thread-1持有R2的锁等待获取R1的锁。
3.4 显式锁(Lock) 从JDK5开始,JUC中提供的锁都提供了常用的锁操作,加锁和解锁的方法都是显式的,我们称他们为显式锁。
JUC中的Lock是一个锁接口,在它下面提供了各种各样的实现类,供我们灵活的使用!
3.4.1 锁的分类 (1)可重入锁和不可重入锁 可重入锁 也叫作递归锁,指的是一个线程可以多次抢占同一个锁。
例如,线程A在进入外层函数抢占了锁之后,当线程A继续进入内层函数时,线程A依然可以再抢到这把锁。
不可重入锁 与可重入锁相反,指的是一个线程只能抢占一次同一个锁。
1 2 Java的synchronized关键字和ReentrantLock类提供的锁都是可重入的。 可重入锁可以有效避免因先后获取同一把锁而导致的死锁。
(2)悲观锁和乐观锁 悲观锁 ,每次进入临界区操作数据的时候都认为别的线程会修改,有安全问题,所以线程每次在读写数据时都会上锁,锁住同步资源,这样其他线程需要读写这个数据时就会阻塞,一直等到拿到锁。
总体来说,悲观锁适用于写多读少的场景,遇到高并发写时性能高。
乐观锁 ,每次进入临界区操作数据的时候都认为别的线程不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样就更新),如果失败就要重复 “读-比较-写”的操作。
总体来说,乐观锁适用于读多写少的场景,遇到高并发写时性能低。
1 synchronized和ReentrantLock都是悲观锁.
(3)公平锁和非公平锁 公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。
非公平锁则是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待,但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。
1 synchronized 是非公平锁,ReentrantLock既可以实现公平也可以非公平。
(4)可中断锁和不可中断锁 可中断锁:线程在等待获取锁的过程中,如果收到中断信号,会立即响应中断,并结束等待状态,这种机制允许线程在等待期间执行其他任务或进行其他操作。
不可中断锁:线程一旦开始等待获取锁,除非成功获取到锁,否则不会被任何中断信号所打断。线程会一直等待,直到成功获取到锁或者线程本身被终止。在等待期间,线程无法响应中断信号,也无法执行其他任务。
1 2 Java中的synchronized关键字实现的就是一种不可中断锁的机制。 Java中的ReentrantLock类支持可中断锁,即线程在等待获取锁时可以被中断。
(5)共享锁和独占锁 独占锁(Exclusive Lock)和共享锁(Shared Lock)。
独占锁也叫互斥锁。当一个线程获得一个独占锁后,其他线程将无法获取该锁,直到该线程释放锁。
共享锁,允许多个线程同时获取同一个锁。
1 2 synchronized 是一种独占锁。 ReentrantLock可以独占也可共享。
3.4.2 使用ReentrantLock改造抢红包案例 ReentrantLock是Lock接口下的一个子类,被称之为可重入锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class RedPackageThread implements Runnable { private static int redPackageCount = 3 ; private static final Lock lock = new ReentrantLock () ; @Override public void run () { lock.lock(); if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); } lock.unlock(); } }
3.4.3 ReentrantLock-可重入锁 可重入锁又名递归锁,Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁 。
给抢红包案例添加检查剩余红包功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class RedPackageThread implements Runnable { private static int redPackageCount = 3 ; private static final Lock lock = new ReentrantLock () ; @Override public void run () { lock.lock(); if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); }else { try { TimeUnit.SECONDS.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); checkReadPackage(); } lock.unlock(); } public void checkReadPackage () { lock.lock(); System.out.println("检查剩余红包......." ); lock.unlock(); } }
3.4.4 ReentrantLock-公平锁/非公平锁 ReentrantLock 默认实现公平锁(也可以实现非公平锁),多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁 。
1 2 private static final Lock lock1 = new ReentrantLock (true ) ; private static final Lock lock2 = new ReentrantLock (false ) ;
3.4.5 ReentrantLock-可中断锁 获取锁方法:lockInterruptibly() 。当有可用锁时会直接得到锁并立即返回,如果没有可用锁会一直阻塞等待直到获取锁,但和 lock() 方法不同的是,lockInterruptibly() 方法在等待获取时,如果遇到线程中断会放弃获取锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class RedPackageThread implements Runnable { private static int redPackageCount = 3 ; private static final Lock lock = new ReentrantLock (); @Override public void run () { try { lock.lockInterruptibly(); if (redPackageCount <= 0 ) { System.out.println(Thread.currentThread().getName() + "---->未抢到红包" ); } else { try { TimeUnit.SECONDS.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"---->抢到了一个红包,剩余红包个数:" + --redPackageCount); } } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } } } public class RedPackageThreadDemo01 { public static void main (String[] args) throws InterruptedException { RedPackageThread redPackageThread = new RedPackageThread () ; Thread t1 = new Thread (redPackageThread , "张三" ) ; Thread t2 = new Thread (redPackageThread , "李四" ) ; Thread t3 = new Thread (redPackageThread , "王五" ) ; Thread t4 = new Thread (redPackageThread , "赵六" ) ; t1.start(); t2.start(); Thread.sleep(5000 ); t2.interrupt(); t3.start(); t4.start(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 java.lang.InterruptedException at java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireInterruptibly(AbstractQueuedSynchronizer.java:959) at java.base/java.util.concurrent.locks.ReentrantLock$Sync.lockInterruptibly(ReentrantLock.java:161) at java.base/java.util.concurrent.locks.ReentrantLock.lockInterruptibly(ReentrantLock.java:372) at com.atguigui.jvm.a.RedPackageThread.run(RedPackageThread.java:19) at java.base/java.lang.Thread.run(Thread.java:833) Exception in thread "李四" java.lang.IllegalMonitorStateException at java.base/java.util.concurrent.locks.ReentrantLock$Sync.tryRelease(ReentrantLock.java:175) at java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.release(AbstractQueuedSynchronizer.java:1007) at java.base/java.util.concurrent.locks.ReentrantLock.unlock(ReentrantLock.java:494) at com.atguigui.jvm.a.RedPackageThread.run(RedPackageThread.java:36) at java.base/java.lang.Thread.run(Thread.java:833) 张三---->抢到了一个红包,剩余红包个数:2 王五---->抢到了一个红包,剩余红包个数:1 赵六---->抢到了一个红包,剩余红包个数:0
3.4.6 tryLock尝试获取锁/限时返回 1 2 3 4 5 6 7 8 9 10 11 12 13 boolean b = lock.tryLock(); if (lock.tryLock()) { try { } finally { lock.unlock(); } } else { }
1 2 3 4 5 6 7 8 9 10 11 if (lock.tryLock(3 , TimeUnit.SECONDS)) { try { } finally { lock.unlock(); } } else { }
3.5 synchronized和Lock对比 (1)synchronized是Java的关键字,在jvm层面上实现的锁;Lock是JUC包下的一个接口。
(2)synchronized 和 ReentrantLock 都是可重入,前者的加速和解锁是自动进行,不用操心锁是否释放;后者需要手动加锁和释放锁,且次数必须一致。
(3)synchronized是独占的,ReentrantLock可独占也可共享。
(4)synchronized 关键字在获取锁时是不可中断的,一个线程获取不到锁就一直等着。ReentrantLock可中断。
(5)在竞争不激烈的情况下,synchronized 的性能与 ReentrantLock 相当。但在高竞争的情况下,ReentrantLock 提供了更灵活的策略(如尝试锁、超时锁等),可能会提供更好的性能。
(6)synchronized 关键字在发生异常时会自动释放锁。使用 Lock 时,如果代码中没有正确处理异常(即没有在 finally 块中释放锁),则可能导致死锁。因此,使用 Lock 时需要更加小心。
3.6 ReentrantReadWriteLock 3.6.1 概述 JAVA中提供的关键字synchronized和JUC包中实现了Lock接口的ReentrantLock ,它们都是独占式获取锁,也就是在同一时刻只有一个线程能够获取锁==》独占锁。
而在一些业务场景中,大部分是读操作,少部分是写操作,如果只是并发读操作的话并不会影响数据正确性,而如果在这种业务场景下,依然使用独占锁的话,效率很差。
针对这种读多写少的情况,java还提供了另外一个实现Lock接口的ReentrantReadWriteLock (读写锁)。
读写锁的特点:
1、写写不可并发
2、读写不可并发
3、写读不可并发
4、读读可以并发
3.6.2 读写并发问题演示 接下来以缓存为例用代码演示读写锁,演示读写并发问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class MyCache { private Map<String, String> cache= new HashMap <>(); public void put (String key, String value) { try { System.out.println(Thread.currentThread().getName() + " 开始写入!" ); Thread.sleep(300 ); cache.put(key, value); System.out.println(Thread.currentThread().getName() + " 写入成功!" ); } catch (InterruptedException e) { e.printStackTrace(); } finally { } } public void get (String key) { try { System.out.println(Thread.currentThread().getName() + " 开始读出!" ); Thread.sleep(300 ); String value = cache.get(key); System.out.println(Thread.currentThread().getName() + " 读出成功!" + value); } catch (InterruptedException e) { e.printStackTrace(); } finally { } } } public class ReentrantReadWriteLockDemo { public static void main (String[] args) { MyCache cache = new MyCache (); for (int i = 1 ; i <= 5 ; i++) { String num = String.valueOf(i); new Thread (()->{ cache.put(num, num); }, num).start(); } for (int i = 1 ; i <= 5 ; i++) { String num = String.valueOf(i); new Thread (()->{ cache.get(num); }, num).start(); } } }
打印结果:多执行几次,就会出现数据读取问题
3.6.3 读写锁的使用 使用读写锁对上述操作进行改造
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class MyCache { private Map<String, String> cache= new HashMap <>(); private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock (); public void put (String key, String value) { rwl.writeLock().lock(); try { System.out.println(Thread.currentThread().getName() + " 开始写入!" ); Thread.sleep(500 ); cache.put(key, value); System.out.println(Thread.currentThread().getName() + " 写入成功!" ); } catch (InterruptedException e) { e.printStackTrace(); } finally { rwl.writeLock().unlock(); } } public void get (String key) { rwl.readLock().lock(); try { System.out.println(Thread.currentThread().getName() + " 开始读出!" ); Thread.sleep(500 ); String value = cache.get(key); System.out.println(Thread.currentThread().getName() + " 读出成功!" + value); } catch (InterruptedException e) { e.printStackTrace(); } finally { rwl.readLock().unlock(); } } }
3.6.4 锁降级 锁降级 :锁降级就是从写锁降级成为读锁 。
在当前线程拥有写锁的情况下,之后再获取到读锁,随后释放写锁的过程就是锁降级。
1 锁降级使用场景:当多线程情况下,更新完数据后,立刻查询刚更新完的数据。
ReentrantReadWriteLock 支持锁降级,不支持锁升级。
4 线程间通讯 线程间通讯概述:线程间通信指的就是让多个线程进行协同工作,来完成特定的任务。
线程间通信,方案一: synchronized + wait() + notify()/notifyAll() 方法二:Lock + Condition
1.1 单生产单消费 1.1.1 需求分析 需求:两个线程操作一个初始值为0的变量,实现一个线程对变量增加1,一个线程对变量减少1,交替10轮。
1.1.2 代码演示 共享变量的类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class ShareDataOne { private Integer number = 0 ; public synchronized void increment () throws InterruptedException { if (number != 0 ) { this .wait(); } number++; System.out.println(Thread.currentThread().getName() + ": " + number); this .notifyAll(); } public synchronized void decrement () throws InterruptedException { if (number != 1 ) { this .wait(); } number--; System.out.println(Thread.currentThread().getName() + ": " + number); this .notifyAll(); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class NotifyWaitDemo { public static void main (String[] args) { ShareDataOne shareDataOne = new ShareDataOne (); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.increment(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "AAA" ).start(); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.decrement(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "BBB" ).start(); } }
1.1.3 sleep和wait的区别 区别:
1、sleep是Thread类中方法,wait方法是Object类中的方法
2、sleep方法不会释放同步锁,wait方法会释放同步锁
1.2 多生产多消费 1.2.1 虚假唤醒问题 (1)问题演示 上述的等待唤醒机制只适用于单生产者和单消费者模型。如果是多生产者多消费者模式,此时就会出现问题。
改造mian方法,加入CCC和DDD两个线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public class NotifyWaitDemo { public static void main (String[] args) { ShareDataOne shareDataOne = new ShareDataOne (); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.increment(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "AAA" ).start(); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.decrement(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "BBB" ).start(); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.increment(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "CCC" ).start(); new Thread (()->{ for (int i = 0 ; i < 10 ; i++) { try { shareDataOne.decrement(); } catch (InterruptedException e) { e.printStackTrace(); } } }, "DDD" ).start(); } }
(2)虚假唤醒说明 换成4个线程会导致错误,虚假唤醒
原因:在java多线程判断时,不能用if,程序出事出在了判断上面。
注意,消费者被唤醒后是从wait()方法(被阻塞的地方)后面执行,而不是重新从同步块开头。
如下图: 出现-1的情况分析!
解决虚假唤醒:查看API,java.lang.Object的wait方法
中断和虚假唤醒是可能产生的,所以要用loop循环,if只判断一次,while是只要唤醒就要拉回来再判断一次。
1.2.2 问题解决 if换成while
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class ShareDataOne { private Integer number = 0 ; public synchronized void increment () throws InterruptedException { while (number != 0 ) { this .wait(); } number++; System.out.println(Thread.currentThread().getName() + ": " + number); this .notifyAll(); } public synchronized void decrement () throws InterruptedException { while (number != 1 ) { this .wait(); } number--; System.out.println(Thread.currentThread().getName() + ": " + number); this .notifyAll(); } }
1.3 Lock+Condition实现通信 condition.await(); 线程等待
condition.signalAll(); 唤醒在此Condition上等待的所有线程
1.3.1 案例改造 代码改造:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class ShareDataOne { private Integer number = 0 ; private static final ReentrantLock reentrantLock = new ReentrantLock () ; private static final Condition condition = reentrantLock.newCondition() ; public void increment () throws InterruptedException { reentrantLock.lock(); while (number != 0 ) { condition.await(); } number++; System.out.println(Thread.currentThread().getName() + ": " + number); condition.signalAll(); reentrantLock.unlock(); } public void decrement () throws InterruptedException { reentrantLock.lock(); while (number != 1 ) { condition.await(); } number--; System.out.println(Thread.currentThread().getName() + ": " + number); condition.signalAll(); reentrantLock.unlock(); } }
1.3.2 打印数字和字母 有两个线程,一个线程打印1-52,另一个打印字母A-Z,打印顺序为 1 2 A 3 4 B … 51 52 Z,要求用线程间通信。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public class PrinterData { private static final Lock lock = new ReentrantLock () ; private static final Condition condition = lock.newCondition() ; public void printNumber () { lock.lock(); for (int x = 1 ; x <= 52 ; x++) { System.out.print(x); if (x % 2 == 0 ) { try { condition.signalAll(); condition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } } lock.unlock(); } public void printChar () { lock.lock(); for (char x = 'A' ; x <= 'Z' ; x++) { System.out.print(x); try { condition.signalAll(); condition.await(); } catch (InterruptedException e) { e.printStackTrace(); } } lock.unlock(); } } public class PrinterDataDemo01 { public static void main (String[] args) { PrinterData printerData = new PrinterData () ; new Thread (() -> { printerData.printNumber(); }).start(); new Thread (() -> { printerData.printChar(); }).start(); } }
5 线程状态 2.1 状态介绍 Java中的线程状态被定义在了java.lang.Thread.State枚举类中,State枚举类的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Thread { public enum State { NEW , RUNNABLE , BLOCKED , WAITING , TIMED_WAITING , TERMINATED; } public State getState () { return jdk.internal.misc.VM.toThreadState(threadStatus); } }
通过源码我们可以看到Java中的线程存在6种状态,每种线程状态的含义如下
线程状态
具体含义
NEW
一个尚未启动的线程的状态。也称之为初始状态、开始状态。线程刚被创建,但是并未启动。还没调用start方法。MyThread t = new MyThread()只有线程象,没有线程特征。
RUNNABLE
调用线程对象的start方法,此时线程进入了RUNNABLE状态。(就绪状态)
BLOCKED
当一个线程试图获取一个对象锁,而该对象锁被其他的线程持有,则该线程进入Blocked状态;
WAITING
一个正在等待的线程的状态,也称之为等待状态。
TIMED_WAITING
一个在限定时间内等待的线程的状态,也称之为限时等待状态。造成线程限时等待状态的原因有三种,分别是:sleep(long)、wait(long)、join(long)。
TERMINATED
一个完全运行完成的线程的状态。也称之为终止状态、结束状态。
各个状态的转换,如下图所示:
2.2 线程状态转换 2.2.1 案例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class ThreadStateDemo01 { public static void main (String[] args) throws InterruptedException { Thread thread = new Thread (() -> { System.out.println("2.执行thread.start()之后,线程的状态:" + Thread.currentThread().getState()); try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("4.执行Thread.sleep(long)完成之后,线程的状态:" + Thread.currentThread().getState()); }); System.out.println("1.通过new初始化一个线程,但是还没有start()之前,线程的状态:" + thread.getState()); thread.start(); Thread.sleep(50 ); System.out.println("3.执行Thread.sleep(long)时,线程的状态:" + thread.getState()); Thread.sleep(100 ); System.out.println("5.线程执行完毕之后,线程的状态:" + thread.getState() + "\n" ); } }
2.2.2 案例二 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class ThreadStateDemo02 { public static void main (String[] args) throws InterruptedException { Object obj = new Object (); Thread thread1 = new Thread (() -> { System.out.println("2.执行thread.start()之后,线程的状态:" + Thread.currentThread().getState()); synchronized (obj) { try { Thread.sleep(100 ); obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("4.被object.notify()方法唤醒之后,线程的状态:" + Thread.currentThread().getState()); }); System.out.println("1.通过new初始化一个线程,但是还没有start()之前,线程的状态:" + thread1.getState()); thread1.start(); Thread.sleep(150 ); System.out.println("3.执行object.wait()时,线程的状态:" + thread1.getState()); new Thread (() -> { synchronized (obj) { obj.notify(); } }).start(); Thread.sleep(10 ); System.out.println("5.线程执行完毕之后,线程的状态:" + thread1.getState() + "\n" ); } }
6 线程池 3.1 线程池概述 线程池(Thread Pool)是一种多线程处理形式,处理过程中将任务提交给线程池,线程池中的线程会异步地执行这些任务。线程池的主要目的是复用线程,减少线程的创建和销毁开销,提高程序的响应速度和吞吐量。
在Java中,java.util.concurrent 包提供了对线程池的支持,包括 ExecutorService 接口和几个实现了该接口的类,如 ThreadPoolExecutor 和 Executors。
优势:
降低资源消耗 :通过复用线程,减少了线程的创建和销毁次数,降低了线程的创建和销毁的开销。提高响应速度 :当任务到达时,任务可以不需要等待线程创建就能立即执行。提高线程的可管理性 :线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性。使用线程池可以对线程进行统一分配、调优和监控。
3.2 JDK中线程池 3.2.1 线程池的体系结构 JDK提供的线程池的体系结构如下所示:
Java中的线程池是通过Executor框架实现的,该框架用到了Executor , Executors , ExecutorService , ThreadPoolExecutor。
3.2.2 Executors工具类 (1)创建线程池方法 Executors 是 JDK 所提供的线程池 工具类,在该类中提供了很多的静态方法 供我们快速的创建线程池对象。
1 2 3 4 5 6 7 8 9 10 11 ExecutorService newCachedThreadPool () ExecutorService newFixedThreadPool (int nThreads) ExecutorService newSingleThreadExecutor () ScheduledExecutorService newSingleThreadScheduledExecutor ()
返回值就是线程池对象ExecutorService,ScheduledExecutorService。
ExecutorService中的常见方法
1 2 Future<?> submit(Runnable task): 向线程池提交任务 void shutdown () : 关闭线程池
(2)newCachedThreadPool 无限大线程池 :newCachedThreadPool的线程池大小理论上可以是无限的,因为它没有设置最大线程数。当执行第二个任务时,如果第一个任务的线程已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ExecutorsDemo01 { public static void main (String[] args) throws InterruptedException { ExecutorService threadPool = Executors.newCachedThreadPool(); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.shutdown(); } }
控制台输出结果
1 2 pool-1 -thread-2 ---执行了任务 pool-1 -thread-1 ---执行了任务
针对每一个任务,线程池为其分配一个线程去执行,我们可以在第二次提交任务的时候,让主线程休眠一小会儿,看程序的执行结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ExecutorsDemo02 { public static void main (String[] args) throws InterruptedException { ExecutorService threadPool = Executors.newCachedThreadPool(); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); TimeUnit.SECONDS.sleep(2 ); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.shutdown(); } }
控制台输出结果
1 2 pool-1 -thread-1 ---执行了任务 pool-1 -thread-1 ---执行了任务
我们发现是通过一个线程执行了两个任务。此时就说明线程池中的线程”pool-1-thread-1”被线程池回收了,成为了空闲线程,当我们再次提交任务的时候,该线程就去执行新的任务。
(3)newFixedThreadPool 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExecutorsDemo03 { public static void main (String[] args) { ExecutorService threadPool = Executors.newFixedThreadPool(3 ); for (int x = 0 ; x < 5 ; x++) { threadPool.submit( () -> { System.out.println(Thread.currentThread().getName() + "----->>>执行了任务" ); }); } threadPool.shutdown(); } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-3 ----->>>执行了任务
通过控制台的输出结果,我们可以看到5个任务是通过3个线程进行执行的,说明此线程池中存在三个线程对象。
(4)newSingleThreadExecutor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExecutorsDemo04 { public static void main (String[] args) { ExecutorService threadPool = Executors.newSingleThreadExecutor(); for (int x = 0 ; x < 5 ; x++) { threadPool.submit(() -> { System.out.println(Thread.currentThread().getName() + "----->>>执行了任务" ); }); } threadPool.shutdown(); } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务
通过控制台的输出结果,我们可以看到5个任务是通过1个线程进行执行的,说明此线程池中只存在一个线程对象。
(5)newSingleThreadScheduledExecutor 支持定时及周期性任务执行。
测试1(演示定时执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ExecutorsDemo05 { public static void main (String[] args) { ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); threadPool.schedule( () -> { System.out.println(Thread.currentThread().getName() + "---->>>执行了该任务" ); } , 10 , TimeUnit.SECONDS) ; threadPool.shutdown(); } }
测试2(演示周期性执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ExecutorsDemo06 { public static void main (String[] args) { ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); threadPool.scheduleAtFixedRate( () -> { System.out.println(Thread.currentThread().getName() + "---->>>执行了该任务" ); } , 10 ,1 , TimeUnit.SECONDS) ; } }
3.3.3 ThreadPoolExecutor (1)基本介绍 刚才我们是通过Executors中的静态方法去创建线程池的,通过查看源代码我们发现,其底层都是通过ThreadPoolExecutor构建的。
比如:newFixedThreadPool方法的源码
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) { return new ThreadPoolExecutor (nThreads, nThreads,0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>()); }
ThreadPoolExecutor最完整的构造方法:
1 2 3 4 5 6 7 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
参数说明
1 2 3 4 5 6 7 corePoolSize: 核心线程的最大值,不能小于0 maximumPoolSize:最大线程数,不能小于等于0 ,maximumPoolSize >= corePoolSize keepAliveTime: 空闲线程最大存活时间,不能小于0 unit: 时间单位 workQueue: 任务队列,不能为null threadFactory: 创建线程工厂,不能为null handler: 任务的拒绝策略,不能为null
(2)阻塞队列简介 jdk1.5 提供了一个BlockingQueue 接口,它主要的用途不是作为容器,而是作为多线程协作的工具。
继承体系图:
BlockingQueue的特征:
1、当生产者线程试图向BlockingQueue中放入元素时,如果队列已满,则线程被阻塞。
2、当消费者线程试图从BlockingQueue中取元素时,如果队列没有元素,则该线程被阻塞。
和阻塞相关的两个方法:
1 2 void put (E e) throws InterruptedException; E take () throws InterruptedException;
BlockingQueue的常用实现类:
1 2 ArrayBlockingQueue: 基于数组实现的有界阻塞队列,有界指的是队列有大小限制 LinkedBlockingQueue: 基于链表实现的无界阻塞队列,并不是绝对的无界(容量:Integer.MAX_VALUE)
我们以ArrayBlockingQueue举例来演示一下阻塞队列的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class ArrayBlockingQueueDemo { public static void main (String[] args) throws InterruptedException { ArrayBlockingQueue<String> arrayBlockingQueue = new ArrayBlockingQueue <String>(1 ) ; arrayBlockingQueue.put("java" ); System.out.println(arrayBlockingQueue.take()); System.out.println(arrayBlockingQueue.take()); System.out.println("程序结束了...." ); } }
(3)自定义线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ThreadPoolExecutorDemo01 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 60 , TimeUnit.SECONDS, new ArrayBlockingQueue <Runnable>(3 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor .AbortPolicy()); threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "------>>>执行了任务" ); }); threadPoolExecutor.shutdown(); } }
3.3.4 线程池工作原理 如下图所示
当我们通过submit方法向线程池中提交任务的时候,具体的工作流程如下:
1、客户端每次提交一个任务,线程池就会在核心线程池中创建一个工作线程来执行这个任务。当核心线程池中的线程已满时,则进入下一步操作。
2、把任务试图存储到工作队列中。如果工作队列没有满,则将新提交的任务存储在这个工作队列里,等待核心线程池中的空闲线程执行。如果工作队列满了,则进入下个流程。
3、线程池会再次在非核心线程池区域去创建新工作线程来执行任务,直到当前线程池总线程数量超过最大线程数时,就是按照指定的任务处理策略处理多余的任务。
举例说明:
假如有一个工厂,工厂里面有10个工人(正式员工),每个工人同时只能做一件任务。因此只要当10个工人中有工人是空闲的,来了任务就分配给空闲的工人做;当10个工人都有任务在做时,如果还来了任务,就把任务进行排队等待;
如果说新任务数目增长的速度远远大于工人做任务的速度,那么此时工厂主管可能会想补救措施,比如重新招4个临时工人进来;
然后就将任务也分配给这4个临时工人做;如果说着14个工人做任务的速度还是不够,此时工厂主管可能就要考虑不再接收新的任务或者抛弃前面的一些任务了。当这14个工人当中有人空闲时,而新任务增长的速度又比较缓慢,工厂主管可能就考虑辞掉4个临时工了,只保持原来的10个工人,毕竟请额外的工人是要花钱的。
这里的工厂可以看做成是一个线程池,每一个工人可以看做成是一个线程。其中10个正式员工,可以看做成是核心线程池中的线程,临时工就是非核心线程池中的线程。当临时工处于空闲状态的时候,那么如果空闲的时间超过keepAliveTime所指定的时间,那么就会被销毁。
3.3.5 线程池任务的拒绝策略 RejectedExecutionHandler是jdk提供的一个任务拒绝策略接口,它下面存在4个子类。
1 2 3 4 ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。是默认的策略。 ThreadPoolExecutor.DiscardPolicy: 丢弃任务,但是不抛出异常 这是不推荐的做法。 ThreadPoolExecutor.DiscardOldestPolicy: 抛弃队列中等待最久的任务 然后把当前任务加入队列中。 ThreadPoolExecutor.CallerRunsPolicy: 调用任务的run()方法绕过线程池直接执行。
注:明确线程池最多可执行的任务数 = 队列容量 + 最大线程数
案例演示1 :演示ThreadPoolExecutor.AbortPolicy任务处理策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ThreadPoolExecutorDemo03 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .AbortPolicy()) ; for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 5 6 7 8 9 10 Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@566776ad[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@edf4efb [Wrapped task = com.atguigu.javase.thread.pool.demo04.ThreadPoolExecutorDemo01$$Lambda$14 /0x0000000100066840 @2f7a2457]] rejected from java.util.concurrent.ThreadPoolExecutor@6108b2d7[Running, pool size = 3 , active threads = 3 , queued tasks = 1 , completed tasks = 0 ] at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2055 ) at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:825 ) at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1355 ) at java.base/java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:118 ) at com.atguigu.javase.thread.pool.demo04.ThreadPoolExecutorDemo01.main(ThreadPoolExecutorDemo01.java:20 ) pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务
控制台报错,仅仅执行了4个任务,有一个任务被丢弃了
案例演示2 :演示ThreadPoolExecutor.DiscardPolicy任务处理策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ThreadPoolExecutorDemo02 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .DiscardPolicy()) ; for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务
控制台没有报错,仅仅执行了4个任务,有一个任务被丢弃了
案例演示3 :演示ThreadPoolExecutor.DiscardOldestPolicy任务处理策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ThreadPoolExecutorDemo03 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor; threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .DiscardOldestPolicy()); for (int x = 0 ; x < 5 ; x++) { final int y = x ; threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" + y); }); } } }
控制台输出结果
1 2 3 4 pool-1 -thread-2 ---->> 执行了任务2 pool-1 -thread-1 ---->> 执行了任务0 pool-1 -thread-3 ---->> 执行了任务3 pool-1 -thread-1 ---->> 执行了任务4
由于任务1在线程池中等待时间最长,因此任务1被丢弃。
案例演示4 :演示ThreadPoolExecutor.CallerRunsPolicy任务处理策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ThreadPoolExecutorDemo04 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor; threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .CallerRunsPolicy()); for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务 pool-1 -thread-1 ---->> 执行了任务 main---->> 执行了任务
通过控制台的输出,我们可以看到次策略没有通过线程池中的线程执行任务,而是直接调用任务的run()方法绕过线程池直接执行。
3.3.6 线程池关闭 关闭线程池的两个方法:
1 1 、shutdown():停止接收新任务,已经提交的任务(包括正在跑的和队列中等待的),会继续执行完成。
1 2 3 4 5 2、shutdownNow():停止接收新任务,原来的任务停止执行。 (1)跟 shutdown() 一样,先停止接收新submit的任务; (2)忽略队列里等待的任务; (3)尝试将正在执行的任务interrupt中断; (4)返回未执行的任务列表;
1 awaitTermination(60, TimeUnit.SECONDS) 等待所有任务完成,如果超过此时间仍有未完成的任务,则会返回false。
优雅关闭线程池的方式:
1、调用 ExecutorService 的 shutdown() 方法,这将禁止提交新任务,但已经提交的任务将继续执行,直到完成为止。
2、调用 awaitTermination(60, TimeUnit.SECONDS) 方法,等待所有任务完成,如果超过此时间仍有未完成的任务,则会返回false。
3、返回false,则调用ExecutorService 的 shutdownNow() 方法来中断所有正在执行的任务。
1 2 3 4 executor.shutdown(); if (!executor.awaitTermination(60 , TimeUnit.SECONDS)) { List<Runnable> runnables = executor.shutdownNow(); }
3.3.7 线程池创建方式选择 在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。
而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
7 并发容器类 面试题:请举例说明集合类是不安全的。
4.1 ArrayList线程不安全 4.1.1 问题演示 我们一起先看看下面的程序吧,看你能看出什么问题吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class NotSafeDemo { public static void main (String[] args) { List<String> list = new ArrayList <>(); for (int i = 0 ; i < 20 ; i++) { new Thread (() -> { list.add(UUID.randomUUID().toString()); System.out.println(list); }, "线程" + i).start(); } } }
你觉得能每次都能正常输出吗?
答案是否定的,也许好几次运行程序都不会出错,但是偶尔就会遇上一次的。
会报一个ConcurrentModificationException 的异常,中文名为:并发修改异常。
4.1.2 问题说明 JDK8的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public boolean add (E e) { ensureCapacityInternal(size + 1 ); elementData[size++] = e; return true ; } public String toString () { Iterator<E> it = iterator(); if (! it.hasNext()) return "[]" ; StringBuilder sb = new StringBuilder (); sb.append('[' ); for (;;) { E e = it.next(); sb.append(e == this ? "(this Collection)" : e); if (! it.hasNext()) return sb.append(']' ).toString(); sb.append(',' ).append(' ' ); } } public Iterator<E> iterator () { return new Itr (); } private class Itr implements Iterator <E> { int expectedModCount = modCount; public E next () { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException (); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException (); cursor = i + 1 ; return (E) elementData[lastRet = i]; } final void checkForComodification () { if (modCount != expectedModCount) throw new ConcurrentModificationException (); } }
4.1.3 解决方案 (1)使用Vector来代替ArrayList 我们可以使用Vector来代替ArrayList,Vector是线程的安全的 ,改用Vector进行测试:
1 2 3 4 5 6 7 List<String> list = new Vector <>(); for (int i = 0 ; i < 20 ; i++) { new Thread (() -> { list.add(UUID.randomUUID().toString()); System.out.println(list); }, "线程" + i).start(); }
Vector的源码分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public synchronized boolean add (E e) { modCount++; ensureCapacityHelper(elementCount + 1 ); elementData[elementCount++] = e; return true ; } public E next () { synchronized (Vector.this ) { checkForComodification(); int i = cursor; if (i >= elementCount) throw new NoSuchElementException (); cursor = i + 1 ; return elementData(lastRet = i); } }
(2)使用Collections.synchronizedList() Collections 提供了方法 synchronizedList 保证 list 是同步线程安全的。
Collections 仅包含对集合进行操作或返回集合的静态方法,所以我们通常也称Collections 为集合的工具类。
1 2 3 4 5 6 7 List list = Collections.synchronizedList(new ArrayList <>());for (int i = 0 ; i < 20 ; i++) { new Thread (() -> { list.add(UUID.randomUUID().toString()); System.out.println(list); }, "线程" + i).start(); }
synchronizedList方法源码分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static <T> List<T> synchronizedList (List<T> list) { return (list instanceof RandomAccess ? new SynchronizedRandomAccessList <>(list) : new SynchronizedList <>(list)); } static class SynchronizedRandomAccessList <E> extends SynchronizedList <E> implements RandomAccess {}static class SynchronizedList <E> extends SynchronizedCollection <E> implements List <E> {}public boolean add (E e) { synchronized (mutex) {return c.add(e);} } public String toString () { synchronized (mutex) {return c.toString();} }
(3)CopyOnWrite写时复制容器 4.2 CopyOnWrite容器 4.2.1 CopyOnWrite容器简介 CopyOnWrite容器 (简称COW容器)即写时复制 的容器。
通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后向新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器 。
更新操作开销大(add()、set()、remove()等等),因为要复制整个数组。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。
所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器 。
当然,这个时候会抛出来一个新的问题,也就是读线程数据不一致 的问题。
从JDK1.5 开始 Java 并发包里提供了两个使用 CopyOnWrite 机制 实现 的 并发容器CopyOnWriteArrayList 和 CopyOnWriteArraySet。
CopyOnWriteArrayList类,在其内部维护了一个数组,因此本质上还是一个数组。
再来看看CopyOnWriteArrayList的add方法,该方法使用了可重入锁,因此是线程安全的。
4.2.2 代码改造 使用CopyOnWriteArrayList改造上述代码:
1 2 3 4 5 6 7 8 List list = new CopyOnWriteArrayList () ;for (int i = 0 ; i < 20 ; i++) { new Thread (() -> { list.add(UUID.randomUUID().toString()); System.out.println(list); }, "线程" + i).start(); }
4.3 ConcurrentHashMap容器 4.3.1 HashMap线程不安全 多线程环境下,HashMap是线程不安全 的。
为了保证数据的安全性我们可以使用 Hashtable,但是Hashtable的效率低。
基于以上两个原因我们可以使用 JDK1.5 以后所提供的 ConcurrentHashMap 。
案例1 :演示HashMap线程不安全1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class HashMapNonThreadSafeExample { private static Map<Integer, Integer> map = new HashMap <>(); public static void main (String[] args) throws InterruptedException { for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { for (int j = 0 ; j < 1000 ; j++) { map.put(j, j); } }).start(); } Thread.sleep(2000 ); System.out.println("Map size: " + map.size()); } }
案例2 :演示Hashtable线程安全1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class HashMapNonThreadSafeExample { private static Map<Integer, Integer> map = new Hashtable <>(); public static void main (String[] args) throws InterruptedException { for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { for (int j = 0 ; j < 1000 ; j++) { map.put(j, j); } }).start(); } Thread.sleep(2000 ); System.out.println("Map size: " + map.size()); } }
4.3.2 Hashtable保证线程安全的原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class Hashtable <K,V> extends Dictionary <K,V> implements Map <K,V>, Cloneable, java.io.Serializable { private transient Entry<?,?>[] table; private static class Entry <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Entry<K,V> next; } public synchronized V put (K key, V value) {...} public synchronized V get (Object key) {...} public synchronized int size () {...} ... }
对应的结构如下图所示
Hashtable 保证线程安全性的是使用方法全局锁进行实现的,在线程竞争激烈的情况下HashTable的效率非常低下,因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞状态。
如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
4.3.3 ConcurrentHashMap线程安全 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class HashMapNonThreadSafeExample { private static Map<Integer, Integer> map = new ConcurrentHashMap <>(); public static void main (String[] args) throws InterruptedException { for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { for (int j = 0 ; j < 1000 ; j++) { map.put(j, j); } }).start(); } Thread.sleep(2000 ); System.out.println("Map size: " + map.size()); } }
4.3.4 源码分析 由于ConcurrentHashMap在jdk1.7和jdk1.8的时候实现原理不太相同,因此需要分别来讲解一下两个不同版本的实现原理。
(1)jdk1.7版本 ConcurrentHashMap中的重要成员变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ConcurrentHashMap <K,V>extends AbstractMap <K,V> implements ConcurrentMap <K,V>,Serializable { final Segment<K,V>[] segments; static final class Segment <K,V> extends ReentrantLock implements Serializable { transient volatile int count; transient int modCount; transient int threshold; transient volatile HashEntry<K,V>[] table; final float loadFactor; } static final class HashEntry <K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; } }
对应的结构如下图所示:
简单来讲,就是ConcurrentHashMap 比 HashMap 多了一次hash过程:第1次hash定位到Segment,第2次hash定位到HashEntry,然后链表搜索找到指定节点。
在进行写操作时,只需锁住写元素所在的Segment即可(这种锁被称为分段锁
ConcurrentHashMap的put方法源码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 public class ConcurrentHashMap <K, V> extends AbstractMap <K, V> implements ConcurrentMap <K, V>, Serializable { public V put (K key, V value) { Segment<K,V> s; if (value == null ) throw new NullPointerException (); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null ) s = ensureSegment(j); return s.put(key, hash, value, false ); } static final class Segment <K,V> extends ReentrantLock implements Serializable { final V put (K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) if (e != null ) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break ; } e = e.next; } else { if (node != null ) node.setNext(first); else node = new HashEntry <K,V>(hash, key, value, first); int c = count + 1 ; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null ; break ; } } } finally { unlock(); } return oldValue; } } }
注意:源代码进行简单讲解即可(核心:进行了两次哈希定位以及加锁过程)
(2)jdk1.8版本 在JDK1.8中为了进一步优化ConcurrentHashMap的性能,去掉了Segment分段锁的设计。
在数据结构方面,则是跟HashMap一样,使用一个哈希表table数组(数组 + 链表 + 红黑树) ;
而线程安全方面是结合CAS机制 + 局部锁 实现的,减低锁的粒度,提高性能。
同时在HashMap的基础上,对哈希表table数组和链表节点的value,next指针等使用volatile来修饰,从而实现线程可见性。
ConcurrentHashMap中的重要成员变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class ConcurrentHashMap <K,V> extends AbstractMap <K,V> implements ConcurrentMap <K,V>, Serializable { transient volatile Node<K,V>[] table; static class Node <K,V> implements Map .Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; } static final class TreeNode <K,V> extends Node <K,V> { TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red; } }
对应的结构如下图
当链表的长度超过8并且数组的长度超过64的时候,就会把链表变成树。
ConcurrentHashMap的put方法源码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 public class ConcurrentHashMap <K,V> extends AbstractMap <K,V> implements ConcurrentMap <K,V>, Serializable { public V put (K key, V value) { return putVal(key, value, false ); } final V putVal (K key, V value, boolean onlyIfAbsent) { if (key == null || value == null ) throw new NullPointerException (); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node <K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node <K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; } private static final sun.misc.Unsafe U; static { try { U = sun.misc.Unsafe.getUnsafe(); ... } catch (Exception e) { throw new Error (e); } } static final <K,V> Node<K,V> tabAt (Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long )i << ASHIFT) + ABASE); } static final <K,V> boolean casTabAt (Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) { return U.compareAndSwapObject(tab, ((long )i << ASHIFT) + ABASE, c, v); } }
简单总结:
1、如果当前需要put的key对应的链表在哈希表table中还不存在,则调用casTabAt方法,基于CAS机制来实现添加该链表头结点到哈希表table中,避免该线程在添加该链表头结的时候,其他线程也在添加的并发问题;
2、如果需要添加的链表已经存在哈希表table中,则通过tabAt方法,获取当前最新的链表头结点f,使用synchronized关键字来同步多个线程对该链表的访问。在synchronized(f)同步块里面则是与HashMap一样遍历该链表,如果该key对应的链表节点已经存在,则更新,否则在链表的末尾新增该key对应的链表节点。
8 并发工具类 在JUC并发包里提供了几个非常有用的并发容器和并发工具类,供我们在多线程开发中进行使用。
1.1 CountDownLatch CountDownLatch被称之为倒计数器 ,CountDownLatch允许一个或多个线程等待其他线程完成操作以后,再执行当前线程。
比如我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程,针对这个需求我们就可以使用CountDownLatch来进行实现。
CountDownLatch中count down是倒着数数的意思;CountDownLatch是通过一个计数器来实现的,每当一个线程完成了自己的任务后,可以调用countDown()方法让计数器-1,当计数器到达0时,调用CountDownLatch的await()方法的线程阻塞状态解除,继续执行。
CountDownLatch的相关方法:
1 2 3 public CountDownLatch (int count) public void await () throws InterruptedException public void countDown ()
案例需求:使用CountDownLatch完成上述需求(我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程)
实现思路:在main方法中创建一个CountDownLatch对象,把这个对象作为作为参数传递给其他的两个任务线程
线程任务类1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class CountDownLatchThread01 implements Runnable { private CountDownLatch countDownLatch ; public CountDownLatchThread01 (CountDownLatch countDownLatch) { this .countDownLatch = countDownLatch ; } @Override public void run () { try { Thread.sleep(10000 ); System.out.println("10秒以后执行了CountDownLatchThread01......" ); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); } }
线程任务类2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class CountDownLatchThread02 implements Runnable { private CountDownLatch countDownLatch ; public CountDownLatchThread02 (CountDownLatch countDownLatch) { this .countDownLatch = countDownLatch ; } @Override public void run () { try { Thread.sleep(3000 ); System.out.println("3秒以后执行了CountDownLatchThread02......" ); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class CountDownLatchDemo01 { public static void main (String[] args) { CountDownLatch countDownLatch = new CountDownLatch (2 ) ; CountDownLatchThread01 countDownLatchThread01 = new CountDownLatchThread01 (countDownLatch) ; CountDownLatchThread02 countDownLatchThread02 = new CountDownLatchThread02 (countDownLatch) ; Thread t1 = new Thread (countDownLatchThread01); Thread t2 = new Thread (countDownLatchThread02); t1.start(); t2.start(); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("主线程执行了.... 程序结束了......" ); } }
控制台输出结果
1 2 3 3 秒以后执行了CountDownLatchThread02......10 秒以后执行了CountDownLatchThread01......主线程执行了.... 程序结束了......
CountDownLatchThread02线程先执行完毕,此时 计数器 减1;
CountDownLatchThread01线程执行完毕,此时计数器 减1;当计数器的值为0的时候,主线程阻塞状态解除,主线程向下执行。
1.2 CyclicBarrier CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。
它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
例如:公司召集5名员工开会,等5名员工都到了,会议开始。我们创建5个员工线程,1个开会线程,几乎同时启动,使用CyclicBarrier保证5名员工线程全部执行后,再执行开会线程。
CyclicBarrier的相关方法
1 2 3 4 public CyclicBarrier (int parties, Runnable barrierAction) public int await ()
案例演示:模拟员工开会
实现步骤:
1、创建一个员工线程类(EmployeeThread),该线程类中需要定义一个CyclicBarrier类型的形式参数
2、创建一个开会线程类(MettingThread)
3、测试类
员工线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class EmployeeThread extends Thread { private CyclicBarrier cyclicBarrier ; public EmployeeThread (CyclicBarrier cyclicBarrier) { this .cyclicBarrier = cyclicBarrier ; } @Override public void run () { try { Thread.sleep((int ) (Math.random() * 1000 )); System.out.println(Thread.currentThread().getName() + " 到了! " ); cyclicBarrier.await(); System.out.println(Thread.currentThread().getName() + " 发言! " ); } catch (Exception e) { e.printStackTrace(); } } }
开会线程类
1 2 3 4 5 6 7 8 public class MettingThread extends Thread { @Override public void run () { System.out.println("好了,人都到了,开始开会......" ); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class CyclicBarrierDemo01 { public static void main (String[] args) { CyclicBarrier cyclicBarrier = new CyclicBarrier (5 , new MettingThread ()) ; EmployeeThread thread1 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread2 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread3 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread4 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread5 = new EmployeeThread (cyclicBarrier) ; thread1.start(); thread2.start(); thread3.start(); thread4.start(); thread5.start(); } }
1.3 Semaphore Semaphore字面意思是信号量 的意思,它的作用是控制访问特定资源的线程数目 。
比如给定一个资源数目有限的资源池,假设资源数目为N,每一个线程均可获取一个资源,但是当资源分配完毕时,后来线程需要阻塞等待,直到前面已持有资源的线程释放资源之后才能继续。
Semaphore的常用方法
1 2 3 public Semaphore (int permits ) permits 表示许可线程的数量public void acquire () throws InterruptedException 表示获取许可public void release () 表示释放许可
案例:6辆车抢占3个车位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class SemaphoreDemo { public static void main (String[] args) { Semaphore semaphore = new Semaphore (3 ); for (int i = 0 ; i < 6 ; i++) { new Thread (()->{ try { semaphore.acquire(); System.out.println(Thread.currentThread().getName() + " 抢到了一个停车位!!" ); TimeUnit.SECONDS.sleep(new Random ().nextInt(10 )); System.out.println(Thread.currentThread().getName() + " 离开停车位!!" ); semaphore.release(); } catch (InterruptedException e) { e.printStackTrace(); } }, String.valueOf(i)).start(); } } }
9 volatile关键字 看程序说结果 分析如下程序,说出在控制台的输出结果。
Thread的子类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class VolatileThread extends Thread { private boolean flag = false ; public boolean isFlag () { return flag;} @Override public void run () { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } this .flag = true ; System.out.println("flag=" + flag); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileThreadDemo01 { public static void main (String[] args) { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { if (volatileThread.isFlag()) { System.out.println("执行了" ); } } } }
控制台输出结果
按照我们的分析,当我们把volatileThread线程启动起来以后,在volatileThread线程的run方法中,线程休眠1s,休眠一秒
以后那么flag的值应该为true。
此时我们在主线程中在调用volatileThread线程中的isFlag()方法,返回的就应该true,那么既然是true,那么就会在控制台输
出”执行了”;但是此时在控制台并没有输出该信息,那么这是为什么呢?要想知道原因,那么我们就需要学习一下JMM。
JMM(Java内存模型) 概述:JMM(Java Memory Model,Java内存模型),是java虚拟机规范中所定义的一种内存模型。
JMM描述了Java程序中各种变量(线程共享变量)的访问规则 ,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
特点:
1、所有的线程共享变量都存储于主内存(计算机的RAM)。
2、每个线程拥有自己的工作内存,保留了被线程使用的变量的工作副本。
3、线程对变量的所有的操作(读/写)都必须在自己的工作内存中完成,而不能直接读写主内存中的变量。
4、不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存完成。
问题分析 了解JMM后,再来分析一下之前程序产生问题的原因。
产生问题的流程分析:
1、VolatileThread 线程 从主内存读取到数据放入其对应的工作内存。
2、将工作内存中的 flag 的值更改为true,此时 flag 的值还没有回写主内存。
3、 main 线程 从 主内存 读取 flag=false 并将其放入到自己的工作内存中。
4、VolatileThread 线程 将flag的值 写回到主内存,但是main函数里面的 while(true) 调用的是系统比较底层的代码,速度快,快到没有时间再去读取主内存中的值,所以while(true)读取到的值一直是false。(如果有一个时刻main线程从主内存中读取到了flag的最新值,那么if语句就可以执行,main线程何时从主内存中读取最新的值,我们无法控制)
我们可以让主线程执行慢一点,执行慢一点以后,在某一个时刻,可能就会读取到主内存中最新的flag的值,那么if语句就可以进行执行。
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileThreadDemo02 { public static void main (String[] args) throws InterruptedException { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { if (volatileThread.isFlag()) { System.out.println("执行了======" ); } TimeUnit.MILLISECONDS.sleep(100 ); } } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
此时我们可以看到if语句已经执行了。当然我们在真实开发中可能不能使用这种方式来处理这个问题,那么这个问题应该怎么处理呢?我们就需要学习下一小节的内容。
问题处理 2.4.1 加锁 第一种处理方案,我们可以通过加锁的方式进行处理。
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class VolatileThreadDemo03 { public static void main (String[] args) throws InterruptedException { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { synchronized (volatileThread) { if (volatileThread.isFlag()) { System.out.println("执行了======" ); } } } } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
工作原理说明
对上述代码加锁完毕以后,某一个线程执行该程序的过程如下:
(1)线程获得锁
(2)清空工作内存
(3)从主内存拷贝共享变量最新的值到工作内存成为副本
(4)执行代码
(5)如果有更新数据,则将修改后的副本的值刷新回主内存中
(6)线程释放锁
2.4.2 volatile关键字 第二种处理方案,我们可以通过volatile关键字来修饰flag变量。
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class VolatileThread extends Thread { private volatile boolean flag = false ; public boolean isFlag () { return flag;} @Override public void run () { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } this .flag = true ; System.out.println("flag=" + flag); } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
工作原理说明
执行流程分析
1、VolatileThread线程从主内存读取到数据放入其对应的工作内存
2、将flag的值更改为true,但是这个时候flag的值还没有回写主内存
3、此时main线程读取到了flag的值并将其放入到自己的工作内存中,此时flag的值为false
4、VolatileThread线程将flag的值写到主内存
5、main线程工作内存中的flag变量副本失效
6、main线程再次使用flag时,main线程会从主内存读取最新的值,放入到工作内存中,然后在进行使用。
总结: volatile保证不同线程对共享变量操作的可见性 ,也就是说一个线程修改了volatile修饰的变量,当修改写回主内存时,另外一个线程可以立即看到最新的值。
10 并发编程三特性 可见性 可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看到修改的值。
volatile关键字修饰的共享变量是可以保证可见性的。
原子性 3.2.1 原子性说明 概述:所谓的原子性是指在一次操作或者多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行,多个操作是一个不可以分割的整体 。
比如:从张三的账户给李四的账户转1000元,这个动作将包含两个基本的操作:从张三的账户扣除1000元,给李四的账户增加1000元。这两个操作必须符合原子性的要求,要么都成功要么都失败。
3.2.2 看程序说结果 分析如下程序的执行结果
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class VolatileAtomicThread implements Runnable { private int count = 0 ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { count++ ; System.out.println("count =========>>>> " + count); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 public class VolatileAtomicThreadDemo { public static void main (String[] args) { VolatileAtomicThread volatileAtomicThread = new VolatileAtomicThread () ; for (int x = 0 ; x < 100 ; x++) { new Thread (volatileAtomicThread).start(); } } }
程序分析:我们在主线程中通过for循环启动了100个线程,每一个线程都会对VolatileAtomicThread类中的count加100次。
期望的正确结果是10000,但是真正的执行结果和我们分析的是否一样呢?运行程序(多运行几次),查看控制台输出结果
1 2 3 4 .... count =========>>>> 9997 count =========>>>> 9998 count =========>>>> 9999
通过控制台的输出,我们可以看到最终count的结果可能并不是10000。接下来我们就来分析一下问题产生的原因。
3.2.3 问题分析说明 以上问题主要是发生在count++操作上:
count++操作包含3个步骤:
1、从主内存中读取数据到工作内存
2、对工作内存中的数据进行++操作
3、将工作内存中的数据写回到主内存
count++操作不是一个原子性操作,也就是说在某一个时刻对某一个操作的执行,有可能被其他的线程打断。
产生问题的执行流程分析:
1、假设此时count的值是100,线程A需要对改变量进行自增1的操作,首先它需要从主内存中读取变量count的值。由于CPU的切换关系,此时CPU的执行权被切换到了B线程。A线程就处于就绪状态,B线程处于运行状态。
2、线程B也需要从主内存中读取count变量的值,由于线程A没有对count值做任何修改,因此此时B读取到的数据还是100
3、线程B工作内存中对count执行了+1操作,但是未刷新之主内存中
4、此时CPU的执行权切换到了A线程上,由于此时线程B没有将工作内存中的数据刷新到主内存,因此A线程工作内存中的变量值还是100,没有失效。A线程对工作内存中的数据进行了+1操作。
5、线程B将101写入到主内存
6、线程A将101写入到主内存
虽然计算了2次,但是只对A进行了1次修改。
3.2.4 volatile不保证原子性 我们刚才说到了volatile在多线程环境下只保证了共享变量在多个线程间的可见性,但是不保证原子性 。
那么接下来我们就来做一个测试。测试的思想,就是使用volatile修饰count。
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileAtomicThread implements Runnable { private volatile int count = 0 ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { count++ ; System.out.println("count =========>>>> " + count); } } }
控制台输出结果(需要运行多次)
1 2 3 4 ... count =========>>>> 9997 count =========>>>> 9998 count =========>>>> 9999
通过控制台结果的输出,我们可以看到程序还是会出现问题。因此也就证明volatile关键字是不保证原子性的。
3.2.5 问题处理 解决方案:
1、加锁
2、使用原子类
我们可以给count++操作添加锁 ,那么count++操作就是临界区中的代码,临界区中的代码一次只能被一个线程去执行,所以count++就变成了原子操作。
线程任务类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class VolatileAtomicThread implements Runnable { private int count = 0 ; private Object obj = new Object (); @Override public void run () { for (int x = 0 ; x < 100 ; x++) { synchronized (obj){ count++ ; System.out.println("count =========>>>> " + count); } } } }
控制台输出结果
1 2 3 count =========>>>> 9998 count =========>>>> 9999 count =========>>>> 10000
有序性 1、什么是指令重排?
有序性:代码编写顺序和代码执行顺序一致。
计算机在执行程序时,为了提高性能,编译器和处理器有时会对指令重排 。
如下代码:
1 2 3 4 5 6 public void mySort () { int x = 11 ; int y = 12 ; x = x + 5 ; y = x * x; }
按照正常的顺序进行执行,那么执行顺序应该是:1 2 3 4 。
但是如果发生了指令重排,那么此时的执行顺序可能是: 1 3 2 4 或 2 1 3 4 ;
但是肯定不会出现:4 3 2 1这种顺序,因为处理器在进行重排时候,必须考虑到指令之间的数据依赖性。
2、解决方案:使用volatile修饰变量,可以保证指令的有序性。
11 原子类与CAS算法 AtomicInteger 简介 概述:java 从 JDK1.5 开始提供了 java.util.concurrent.atomic包(简称Atomic包)。
这个包中的 原子操作类 提供了一种 线程安全 地更新一个变量的方式,且简单高效。
因为变量的类型有很多种,Atomic包里一共提供了13个类,属于4种类型的原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性(字段)。
本次我们只讲解使用原子的方式更新基本类型,使用原子的方式更新基本类型Atomic包提供了以下3个类:
AtomicBoolean: 原子更新布尔类型
AtomicInteger: 原子更新整型
AtomicLong: 原子更新长整型
以上3个类提供的方法几乎一模一样,所以本节仅以AtomicInteger为例进行讲解,AtomicInteger的常用方法如下:
1 2 3 4 5 6 7 8 public AtomicInteger () : 初始化一个默认值为0 的原子型Integerpublic AtomicInteger (int initialValue) : 初始化一个指定值的原子型Integerint get () : 获取值int getAndIncrement () : 以原子方式将当前值加1 ,注意,这里返回的是自增前的值。 i++int incrementAndGet () : 以原子方式将当前值加1 ,注意,这里返回的是自增后的值。 ++iint addAndGet (int data) : 以原子方式将输入数值与实例中值(AtomicInteger里的value)相加,并返回结果。int getAndSet (int value) : 以原子方式设置为newValue的值,并返回旧值。
基本使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class AtomicIntegerDemo01 { public static void main (String[] args) { AtomicInteger atomicInteger = new AtomicInteger (5 ) ; System.out.println(atomicInteger); System.out.println(atomicInteger.get()); System.out.println(atomicInteger.getAndIncrement()); System.out.println(atomicInteger.get()); System.out.println(atomicInteger.incrementAndGet()); System.out.println(atomicInteger.addAndGet(8 )); System.out.println(atomicInteger.getAndSet(20 )); System.out.println(atomicInteger.get()); } }
问题解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class VolatileAtomicThread implements Runnable { private AtomicInteger atomicInteger = new AtomicInteger () ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { int i = atomicInteger.incrementAndGet(); System.out.println("count =========>>>> " + i); } } }
控制台输出结果
1 2 3 4 ... count =========>>>> 9998 count =========>>>> 9999 count =========>>>> 10000
通过控制台的执行结果,我们可以看到最终得到的结果就是10000,因此也就证明AtomicInteger所提供的方法是原子性操作方法。
CAS算法 AtomicInteger原理: 自旋锁 + CAS算法
CAS简介 CAS的全称是: Compare And Swap(比较再交换),是一种对内存中的共享数据进行操作的一种特殊指令 。
CAS可以将 read-modify-write 转换为原子操作,这个原子操作直接由CPU保证。
CAS有3个操作数:内存值V(内存中的一个变量),旧的预期值A,要修改的新值B。
当且仅当旧预期值A和内存值V相同时,将内存值V修改为B并返回true,否则什么都不做,并返回false。
举例说明:
在内存值V,存储着值为10的变量。
此时线程1想要把变量的值增加1。对线程1来说,旧的预期值 A = 10 ,要修改的新值 B = 11。
在线程1要提交更新之前,另一个线程2抢先一步,把内存值V中的变量值率先更新成了11。
线程1开始提交更新,首先进行A和内存值V的实际值比较(Compare),发现A不等于V的值,提交失败。
线程1重新获取内存值V作为当前A的值,并重新计算想要修改的新值。此时对线程1来说,A = 11,B = 12。这个重新尝试的过程被称为自旋
这一次比较幸运,没有其他线程改变V的值。线程1进行Compare,发现A和V的值是相等的。
线程1进行SWAP,把内存V的值替换为B,也就是12。
举例说明:这好比春节的时候抢火车票,下手快的会抢先买到票,而下手慢的可以再次尝试,直到买到票。
4.2.2 AtomicInteger源码分析 那么接下来我们就来查看一下AtomicInteger类中incrementAndGet方法的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class AtomicInteger extends Number implements java .io.Serializable { private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe(); private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value" ); private volatile int value; public final int incrementAndGet () { return U.getAndAddInt(this , VALUE, 1 ) + 1 ; } }
UnSafe类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public final class Unsafe { public final int getAndAddInt (Object o, long offset, int delta) { int v; do { v = getIntVolatile(o, offset); } while (!weakCompareAndSetInt(o, offset, v, v + delta)); return v; } public final boolean weakCompareAndSetInt (Object o, long offset, int expected, int x) { return compareAndSetInt(o, offset, expected, x); } public final native boolean compareAndSetInt (Object o, long offset, int expected, int x) ; }
4.2.3 CAS缺点 1、在并发量比较高的情况下,如果反复尝试更新某个变量,却又一直更新不成功,会给CPU带来较大的压力。
2、ABA问题:当变量从A修改为B再修改回A时,变量值等于期望值A,但是无法判断是否修改,CAS操作在ABA修改后依然成功。
3、CAS机制只保证一个变量的原子性操作,而不能保证整个代码块的原子性。
4.2.4 CAS与synchronized CAS和synchronized都可以保证多线程环境下共享数据的安全性。那么他们两者有什么区别?
synchronized是从悲观的角度出发:
总是假设最坏的情况,每次去拿数据的时候都认为别人会 修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。因此synchronized我们也将其称之为悲观锁。jdk中的ReentrantLock也是一种悲观锁。
CAS是从乐观的角度出发:
总是假设最好的情况,每次去拿数据的时候都认为别人不会 修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。CAS这种机制我们也可以将其称之为乐观锁。
12 AQS(抽象队列同步器)-了解 AQS简介 在Java的java.util.concurrent(简称JUC)包中,AbstractQueuedSynchronizer(AQS,抽象队列同步器)是一个核心的基础类,它为依赖于先进先出(FIFO)等待队列的阻塞锁和相关的同步器(如Semaphore、CountDownLatch、ReentrantLock、ReentrantReadWriteLock等)提供了一个框架。
AQS是一个基于状态(通常使用一个volatile的int类型的变量state表示)的同步器,它使用了一个内部的FIFO队列来完成等待线程的管理。这个队列被称为CLH队列,用于在获取不到资源的线程之间进行排队。
作用:
同步状态管理 :AQS使用一个volatile的int类型的变量state来维护同步状态。state为0表示没有线程占用资源,非0表示有线程占用资源。队列管理 :AQS内部维护了一个等待队列,当线程获取不到资源时,会加入到这个队列中进行等待,直到被唤醒或超时。独占模式和共享模式 :AQS支持两种模式的资源访问控制:独占模式和共享模式。独占模式意味着只有一个线程能访问执行;共享模式允许多个线程同时访问执行。
AQS同步队列的head节点是一个空节点,没有记录线程node.thread=null ,其后继节点才是实质性的有线程的节点。
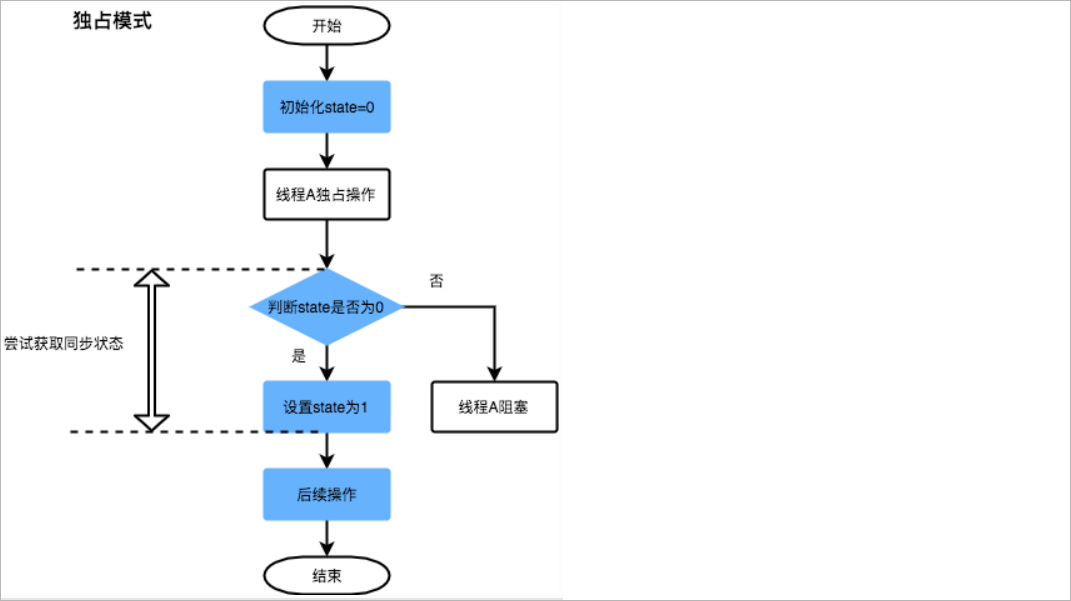
工作模式 独占模式 原理介绍:
独占模式下时,其他线程试图获取该锁将无法取得成功,只有一个线程能执行,如ReentrantLock采用独占模式。
工作流程如下所示:
线程获取锁的流程:
1、线程A获取锁,将state的值由0设置为1
2、在A没有释放锁之前,线程B也来获取锁,线程B获取到state的值为1,表示锁被占用。线程B创建Node节点放入队尾,并且阻塞线程B
3、同理线程C获取到的state的值为1,表示锁被占用。线程C创建Node节点放入队尾,并且阻塞线程C。
线程释放锁的流程:
1、线程A执行完毕以后,将state的值由1设置为0
2、唤醒下一个Node B节点,然后删除线程A节点
以ReentrantLock公平锁为例,获取锁的相关源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 final void lock () { acquire(1 ); } public final void acquire (int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } protected final boolean tryAcquire (int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0 ) { if (!hasQueuedPredecessors() && compareAndSetState(0 , acquires)) { setExclusiveOwnerThread(current); return true ; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0 ) throw new Error ("Maximum lock count exceeded" ); setState(nextc); return true ; } return false ; } hasQueuedPredecessors()方法的作用:通过检查等待队列中是否有其他线程在等待来判断当前线程是否可以立即获取资源。
共享模式 原理说明:
共享模式下,多个线程可以成功获取到锁,多个线程可同时执行。如:Semaphore、CountDownLatch。
工作流程如下所示:
获取锁的流程:
1、线程A判断state的值是否大于0,如果否,则创建Node节点,将其加入到阻塞队列末尾。
2、如果大于0相当于获取到了锁,使用CAS算法对state进行-1
释放锁的流程
1、执行业务操作,业务操作完毕以后对state的值进行+1操作
2、唤醒下一个Node B节点,然后删除线程A节点
源码分析:Semaphore